 热传商务网-热传散热产品智能制造信息平台
热传商务网-热传散热产品智能制造信息平台一、两种主流出货GPU机型概述
GPU服务器按照GPU芯片之间的互联方式可分为两类:
1、PCIE机型:最常规的GPU服务器,GPU间通过PCIE链路进行通信,受限于PCIE带宽上限,卡与卡双向互联带宽低于Nvlink机型,所以在大模型训练方面效率低于SXM机型。
2、Nvlink机型:也叫SXM机型,指的是在服务器内部,GPU卡之间通过Nvlink链路互联,相比PCIE带宽更高,更适合于大模型训练场景。
两种GPU卡的外观展示:

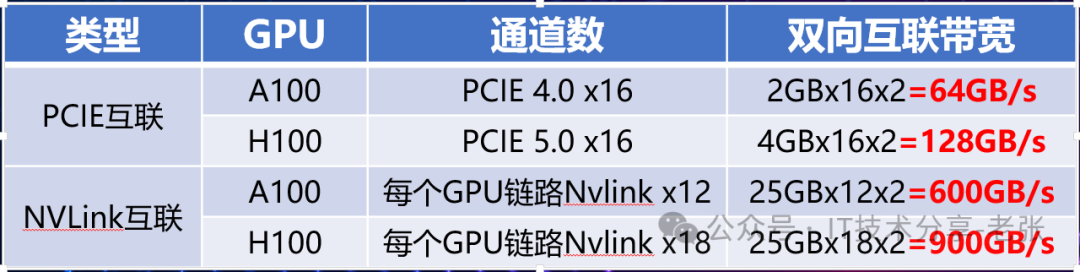
两种GPU互联方案的互联带宽:
二、PCIE 机型的GPU服务器内部互联拓扑
1、标准的GPU服务器CPU和GPU,GPU之间都是通过PCIE链路互联。
2、只能在成对的 GPU之间通过 NVLink 桥接器连接,无法做到全互联。
3、对比SXM机型,PCIE选择灵活,包括GPU卡的数量,以及PCIE的拓扑都可以调整。
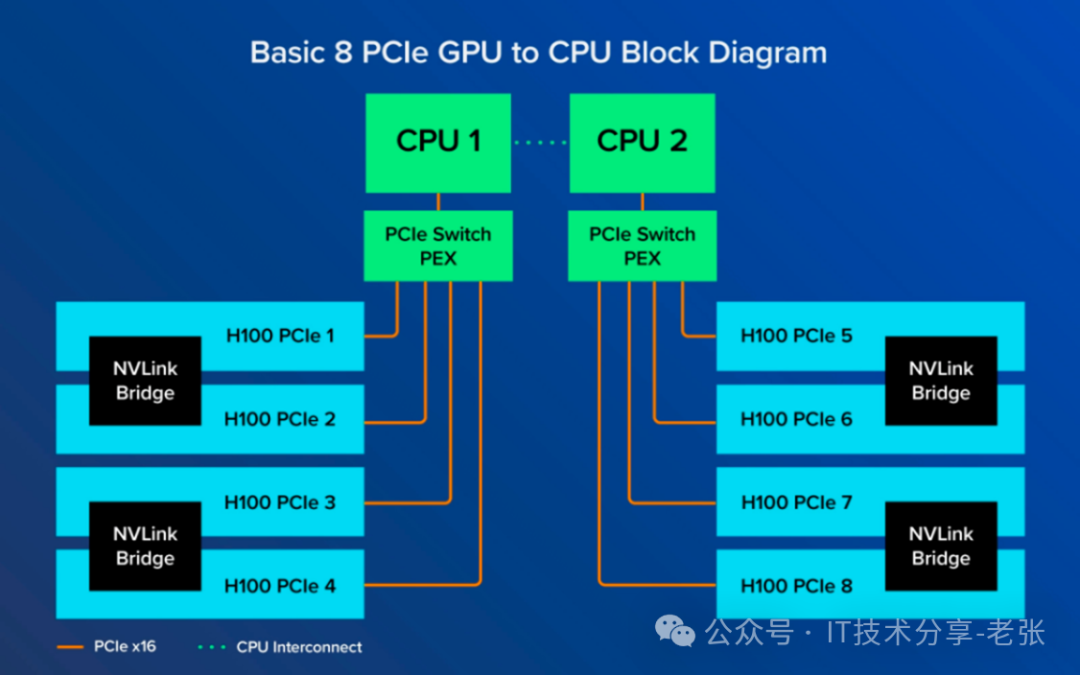
PCIE 机型的GPU互联拓扑可以根据业务场景不同。通过调整主板上PCIE SW的链接线缆可实现不同拓扑的切换,有些厂商宣称可以一键切换,可能其他把线缆全部链接,再通过软件控制。


三、PCIE机型的NVLink扩展(桥接器方案)
为了尽可能的普及Nvlink技术,英伟达专门推出了配套PCIE 高端型号GPU卡的桥接器,通常只能实现两卡之间的互联,局限性强,以A100为例支持最多3个,满配三个时互联带宽可达600GB/s

桥接器互联正确和错误实例
备注:NVLINK桥机器有很多注意事项,比如需要同属于一个CPU下,以及只能相邻槽位等
四、Nvlink机型的核心-HGX模组
Nvlink机型各个厂商都基于英伟达的HGX-GPU模组设计,整机在高度上通常是4U、6U或8U,其中最核心也是价格占比最高是英伟达的GPU模组,可以理解成是有8个物理GPU组成的一个大的逻辑” GPU”。

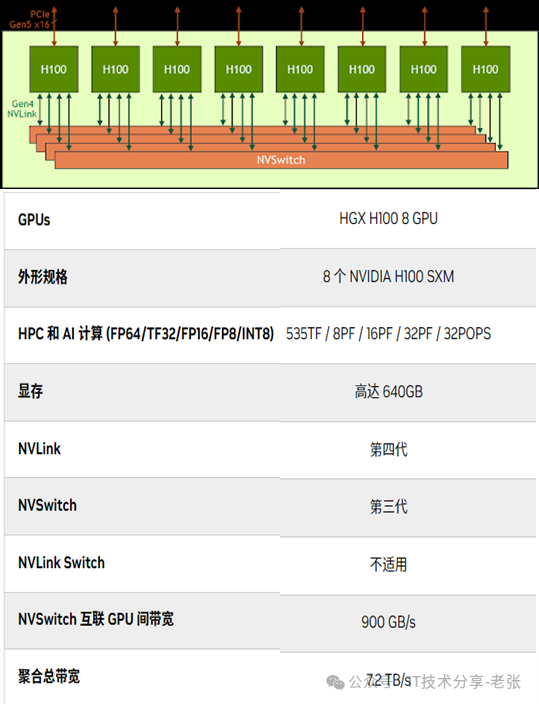
英伟达HGX模组产品图
如下图所示,8张H100芯片通过4个NVSwitch芯片实现了全互联。卡到NVSwitch芯片的链路数量有两种组合,分为4条一组和5条一组,18条的NVLINK对应4个NVSwitch芯片(4条+4条+5条+5条,共18条)。
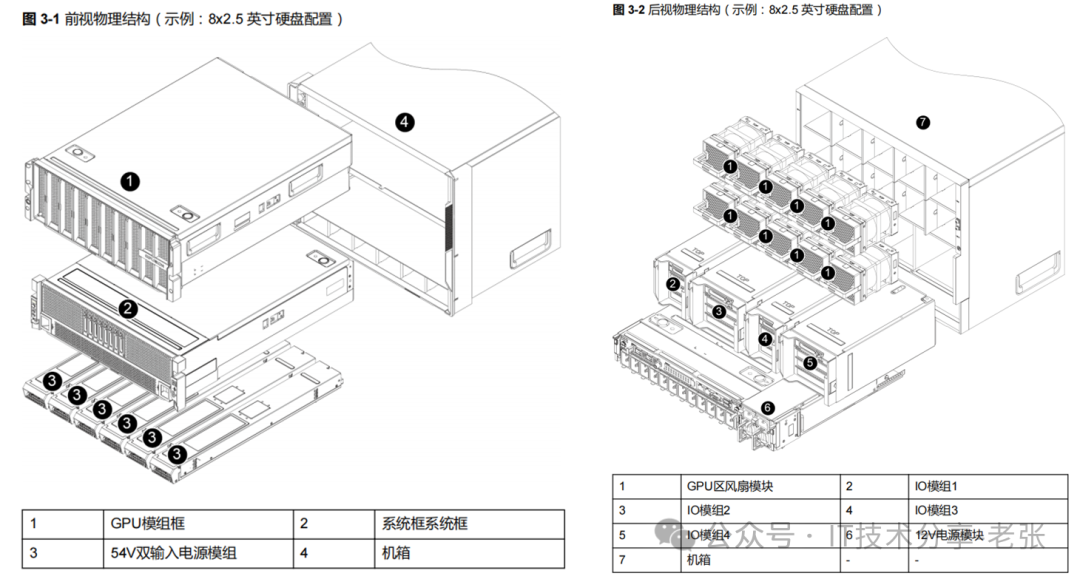
五、Nvlink机型产品形态举例
以超聚变Nvlink H800整机G8600 V7为例,产品采用模块化设计,GPU模组,系统模块,IO模组,风扇模组,电源模组,各个模块均可单独维护。因为厂商围绕HGX模组进行设计,其他部分的差异化较大
六、Nvlink机型-主板逻辑图分析
与PCIE机型的GPU服务器不同,Nvlink机型的主板不需要直接支持GPU。
主板通过四个PCIE Switch提供PCIE通道与HGX模组互联,每个PCIE Switch与2个GPU互联,到每个GPU的链路为PCIEx16。
Intel SPR CPU支持80个PCIE通道,CPU到每个PCIE Switch通常也是PCIEx16。
2个CPU到4个PCIE Switch采用对称设计,架构上实现了PCIE资源的均衡和CPU性能的平均。
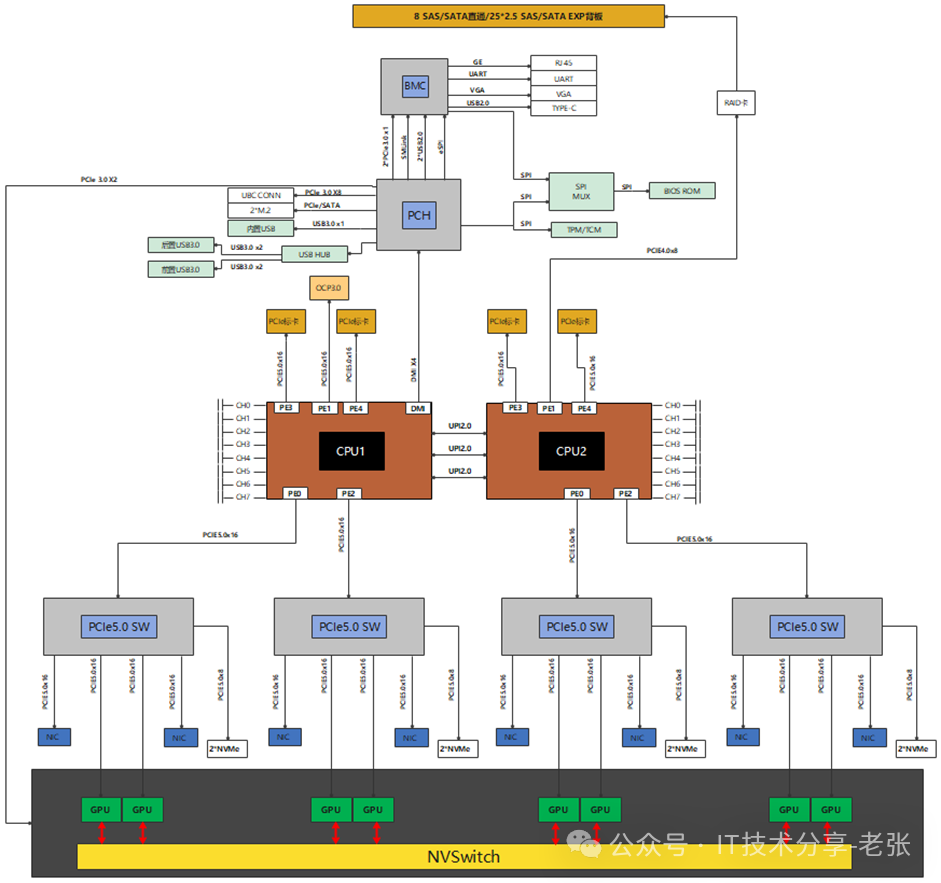
Nvlink解决的是GPU之间的高速互联,GPU与CPU之间的还需要标准的PCIE链路链接。主流的AI大模型依赖于多卡协同,非常吃GPU之间的带宽,因此Nvlink全互联的GPU非常抢手。
来源:IT技术分享-老张
①凡本网注明"信息来源:热传商务网"的所有文章,版权均属于本网,未经本网授权不得转载、摘编或利用其它方式使用。
②来源第三方的信息,本网发布的目的在于分享交流,不做商业用途,亦不保证或承诺内容真实性等。如有侵权,请及时联系本网删除。联系方式:7391142@qq.com



